

The ESA empire truly exploded with the success of PIVOTAL trial, discussed recently on NephJC. This trial was a non-inferiority(NI) trial, and in a subsequent re-analysis also concluded the superiority of high dose IV iron regimen over the low dose regimen. How does one make sense of something that is ‘non-inferior’ and also ‘superior’. Can an intervention be ‘not non-inferior’? Is not ‘non-inferior’ the same as ‘inferior’? The last decade has seen a surge of non-inferiority design in RCTs. Read this great article on multiple examples of non-inferiority trials in the field of cardiology and the lessons learned from them. Hot off the press in the nephrology world is the MENTOR trial, another well designed and conducted NI trial. The PIVOTAL and MENTOR trials are great examples to highlight the differences between non-inferiority, equivalence, and superiority trials and to dwell into some of the following questions
When is it appropriate to choose a non-inferiority trial design?
Is it acceptable to first prove non-inferiority and then prove superiority?
If you design a trial to prove superiority but fail, can you then prove non-inferiority?
Is biocreep real?
Before going into the depths of a non-inferiority trial, lets do a conceptual head to head comparison of the three designs. It is easy to understand the difference between superiority and equivalence trials, but the challenge is to understand the difference between equivalence and non-inferiority designs. These are inherently very different from each other but figuring out the difference can feel like being stuck in a vortex! (At least it was the case for me personally)

When is it appropriate to choose a non-inferiority design instead of superiority?
In other words, why do trialists design a trial to prove a new drug is “not worse” instead of simply proving superiority?
A typical RCT is usually a superiority trial (but is not always labelled so) and the aim is to show that a new intervention, treatment or drug is better than the active control or placebo. Take CREDENCE for example. CREDENCE showed that in patients with type 2 diabetes and kidney disease, the risk of kidney failure and cardiovascular events was lower in the canagliflozin group than in the placebo.
Non inferiority trials are usually designed to show that a particular intervention may be acceptably worse than the current standard of care treatment (control) but has ancillary benefits over the control such as lower costs, lesser side effects, easier administration etc. In case of PIVOTAL trial the investigators hypothesized and proved that a proactive high dose IV iron regimen will be at least non-inferior to current practice of dosing iron reactively, with the added advantage of ability to decrease exposure to ESAs and reducing cardiovascular complications associated with ESAs. In the MENTOR trial, a non-inferiority margin of 15% was chosen based on prior studies on treatment of membranous nephropathy and the investigators hypothesized that even if rituximab was inferior to cyclosporine by 15%, rituximab would have other advantages of being better tolerated, less monitoring of drug levels, improved and certain adherence, and less nephrotoxicity!
Finally, non-inferiority trial design usually requires a smaller sample size as compared to a superiority trial and hence fewer resources. This plays a huge role in lowering the cost of a trial. Lower cost and sample size also makes it a more convenient endeavour!
The magic is in the margin.
Assessing non-inferiority is actually more complex than assessing and proving superiority both in terms of trial design and analysis of results. What makes an intervention “not unacceptably worse” than the standard is based on the definition of the margin of non-inferiority. The NI margin is determined with both clinical and statistical considerations.
An acceptable non-inferiority margin should be pre-specified otherwise it may lead to bias.

Figure 1 beautifully elaborates the differences between the 3 designs. The positive and negative triangles represent the upper and lower bound pre-specified margins. The null hypothesis in a superiority trial states that the two treatments are equal and the trial aims at rejecting the null hypothesis and proving that one treatment is better than the other by Δ. In a superiority trial, upper limit of the confidence interval (CI) of the effect size of one intervention is above zero and crosses the upper bound margin Δ. Sometimes the goal is to show that the two treatments are equivalent. This is again done by choosing a margin, both a lower (-Δ) and upper one(Δ). If the CI of the effect size between the two treatments lies strictly between within the upper and lower margin, the two treatments are concluded to be equivalent. Equivalence trial may be used in showing a new antimicrobial which has less resistance is biologically the same as the generic antibiotic or in showing lot consistency in vaccine trials.
In a non-inferiority trial, the focus is on the lower bound margin, what happens at the upper end is not of primary concern in this type of trial design. One can also declare superiority in a non-inferiority trial if the lower limit of CI of the new treatment is above the non-inferiority margin and above zero. This is acceptable because it usually takes into account and controls for the Type 1 error and does not penalize for multiple testing. Check out our post on multiple testing and Bonferonni correction here. But claiming non-inferiority after you have failed to prove superiority is usually not acceptable unless the trial is designed this way from the start and the non-inferiority margin has been set from the get go.
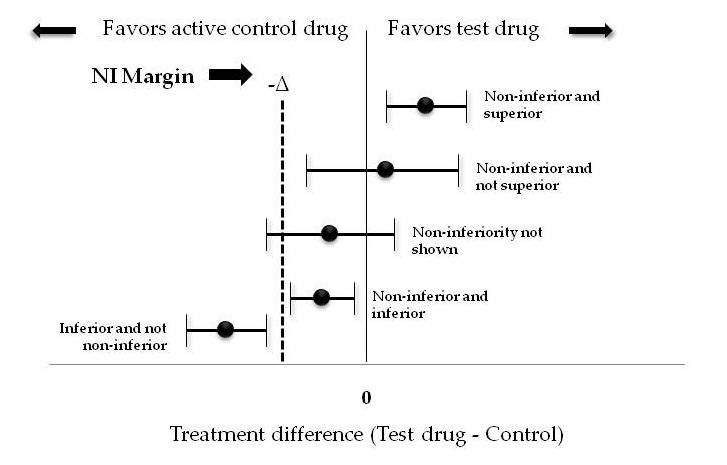
Figure 2 elaborates all the possible outcomes of a non-inferiority trial.
Each horizontal line represents a CI, with the estimated treatment effect denoted by the dot in the center.
If a confidence interval sits entirely above zero, the trial would conclude that the test intervention is superior and hence also non-inferior to the control.
If the lower bound CI sits above the NI margin but is less than zero (CI spans zero), the test intervention is non-inferior but not superior to control.
If the lower limit of CI is less than both zero and the NI margin, it means that non-inferiority is not shown. A good example of this type of trial is the APPAC RCT to compare antibiotic therapy with appendectomy in the treatment of uncomplicated acute appendicitis confirmed by computed tomography. When the trial was designed, the investigators assumed that there would be sufficient benefits from avoiding surgery and that a 24% failure rate in the antibiotic group would be acceptable. Instead, they found a failure rate of 27.3% and were not able to establish the noninferiority of antibiotic treatment for appendicitis. Inability to prove non-inferiority does not conclude that the test intervention is inferior, it only means that it is “not non-inferior”. This outcome could be a result of an underpowered trial. The APPAC trial despite not able to prove its hypothesis was actually a successful trial as it made surgeons rethink the decision of need for emergency appendectomies in uncomplicated appendicitis.
If the entire CI is between NI margin and zero, statistically speaking this proves that the new drug is both non-inferior and inferior to the standard drug which clinically makes no sense. This kind of outcome can occur if the margin is chosen too generously and is very wide. If the entire CI is below the NI margin, it proves that the new intervention is inferior and non-inferiority is not shown. A prespecified fixed margin is commonly derived from estimates of effect size of standard drug over placebo from previous superiority studies.
Other considerations...
A well done non-inferiority trial usually has good assay sensitivity which is the ability of a clinical trial to adequately distinguish between a truly effective vs a non-effective or a less effective treatment. The study must have good assay sensitivity in order to ensure that if a placebo arm was included in the trial, the study would allow showing superiority of the active control . The design and study population of the non-inferiority trial should be similar to the prior trial which has proven the superiority of the active control. These considerations are important to prevent the emergence of ineffective or inferior treatments through non-inferiority trials. This leads us to the concept of technocreep or biocreep.
NI trials: Reader beware
The discussion above is mostly based on optimistic and perhaps pollyannaish theoretical considerations. In a study of published non-inferiority trials, Scott Aberegg and colleagues point out that almost all published NI trials are non-inferior. This is a somewhat implausible result and suggests the potential problem with misuse of the margin. Additionally, they suggest examining the ‘looking glass’ aspect of the NI trials from the other aspect, as to whether these trial outcomes would pass muster for a superiority trial. The figure below shows how this may pan out.

Vinay Prasad throws a light on potential misuses of NI trials in his accompanying commentary titled “Non-Inferiority Trials in Medicine:Practice changing or a self-fulfilling Prophecy?”. Inappropriately wide margin choice in a NI trial can effectively prove an inferior treatment to be non-inferior. Unless the investigators clearly state the purpose of comparing an “acceptably worse” treatment to an established alternative (for its potential ancillary benefits) it is unethical to perform such a trial.
As newer and newer treatments come into the market, drug companies may try to show that their product is at least non-inferior if not superior to the current standard. Lets say a trial proves a drug B is non-inferior to drug A (the current established standard of care). Now if another new drug C claims it is non-inferior to B, is C it still a good drug? We know that B is “acceptably worse” than A, and if we compare C to B, is it really a fair comparison? This phenomenon is called Biocreep where hypothetically newer drugs can be compared to an inferior drug to begin with and successive such comparisons can lead to use of a product which may eventually may not even be better than a placebo. In reality, biocreep does not commonly occur because there is usually one “big gun” drug that everyone is going to try to test against and no good trial will test the new drug against an inferior drug. But it is still important to understand this concept because this is how non-inferiority trials may favor an inferior product if the trial is not rigorously conducted.
One has to wonder: should new drugs be approved or used based on NI trials at all? Shouldn’t they have to prove superiority for some outcomes first? Usually they are more expensive than standard of care, so to pay more for a potentially ‘non-inferior but inferior’ would seem like a travesty. Before anyone points out that the recent SGLT2i trials were NI in design, note that these are NI trials for cardiovascular safety, after their efficacy in glycemia has already been demonstrated. More on that topic is discussed in the introduction of the NephJC discussion for CANVAS. On the other hand, for comparison of an intervention that is implausible in being superior to the control, but still desirable (eg no hydration versus hydration in contrast AKI prophylaxis), an NI trial design is a very appropriate choice. Same applies to more versus less iron, or even rituximab versus cyclosporine (caveat of appropriate NI margin choice).
To conclude, non-inferiority trials do have tremendous utility in modern medicine as more and more drugs or treatments are being developed ever so often and these need to be rigorously tested against established guideline based practices. It is a herculean task to conduct well designed non-inferiority trials and we need to understand the pitfalls in their methodologies to prevent their misuse. Read this excellent review of non-inferiority trials here.